3.1 Introduction
Temporal data arrives in many possible formats, with many different time contexts. For example, time can have various resolutions (hours, minutes, and seconds), and can be associated with different time zones with possible adjustments such as daylight saving time. Time can be regular (such as quarterly economic data or daily weather data), or irregular (such as patient visits to a doctor’s office). Temporal data also often contains rich information: multiple observational units of different time lengths, multiple and heterogeneous measured variables, and multiple grouping factors. Temporal data may comprise the occurrence of time-stamped events, such as flight departures.
Perhaps because of this variety and heterogeneity, little organization or conceptual oversight on how one should get the wild data into a tamed state is available for temporal data. Analysts are expected to do their own data preprocessing and take care of anything else needed to allow further analysis, which leads to a myriad of ad hoc solutions and duplicated efforts.
Wickham and Grolemund (2016) proposed the tidy data workflow, to give a conceptual framework for exploring data (as described in Figure 3.1). In the temporal domain, data with time information arrives at the “import” stage. A new abstraction, tsibble, introduced in this paper, is the gatekeeper at the “tidy” stage, to verify if the raw temporal data is appropriate for downstream analytics. The exploration loop will be aided with declarative grammars, yielding more robust and accurate analyses.
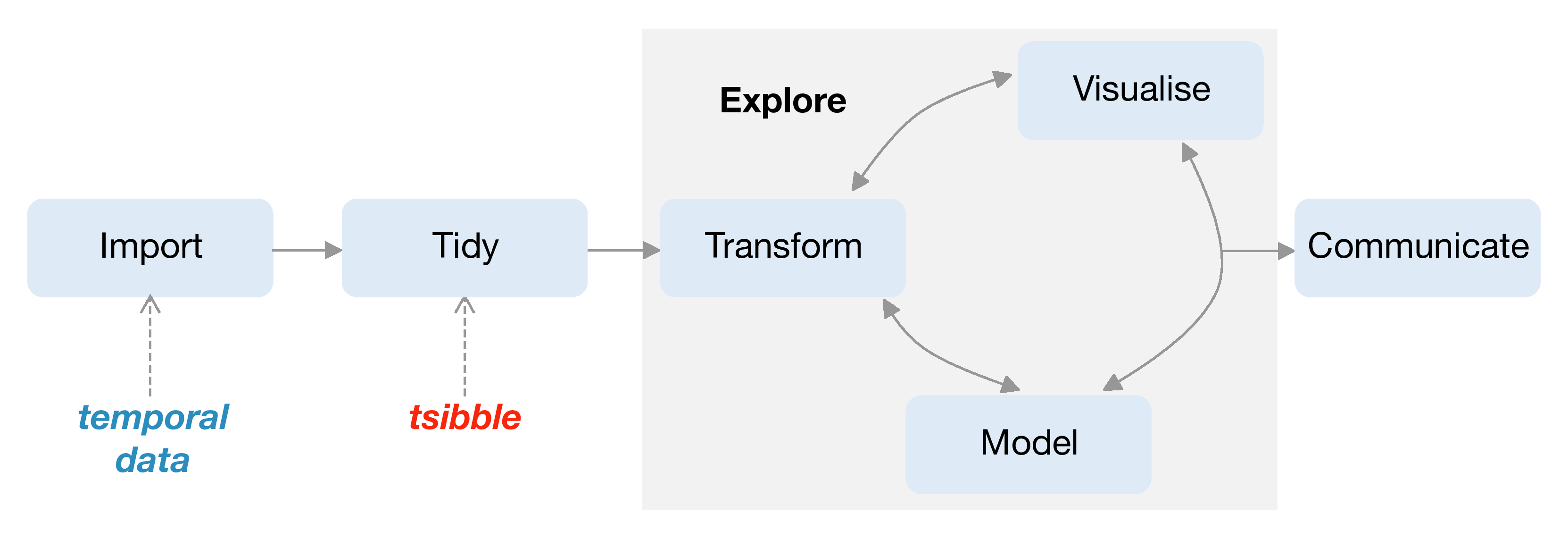
Figure 3.1: Annotation of the data science workflow regarding temporal data, drawn from Wickham and Grolemund (2016). The new data structure, tsibble, makes the connection between temporal data input, and downstream analytics. It provides elements at the “tidy” step, which produce tidy temporal data for temporal visualization and modeling.
The paper is structured as follows. Section 3.2 reviews temporal data structures corresponding to time series and longitudinal analysis, and discusses “tidy data”. Section 3.3 proposes contextual semantics for temporal data, built on top of tidy data principles. The concept of data pipelines, with respect to the time domain, is discussed in depth in Section 3.4, followed by a discussion of the design choices made in the software implementation in Section 3.5. Two case studies are presented in Section 3.6 illustrating temporal data exploration using the new infrastructure. Section 3.7 summarizes current work and discusses future directions.