3.5 Software structure and design decisions
The tsibble package development follows closely to the tidyverse design principles (Tidyverse Team 2019).
3.5.1 Data first
The primary force that drives the software’s design choices is “data”. All functions in the package tsibble start with data or its variants as the first argument, namely “data first”. This lays out a consistent interface and addresses the significance of the data throughout the software.
Beyond the tools, the print display provides a quick and comprehensive glimpse of data in temporal contexts, particularly useful when handling a large collection of data. The contextual information provided by the print() function, shown below from Table 3.1, contains (1) data dimension with its shorthand time interval, alongside time zone if date-times, (2) variables that constitute the “key” with the number of units. These summaries aid users in understanding their data better.
#> # A tsibble: 12 x 5 [1Y]
#> # Key: country, gender [6]
#> country continent gender year count
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Australia Oceania Female 2011 120
#> 2 Australia Oceania Female 2012 125
#> 3 Australia Oceania Male 2011 176
#> 4 Australia Oceania Male 2012 161
#> 5 New Zealand Oceania Female 2011 36
#> # … with 7 more rows3.5.2 Functional programming
Rolling window calculations are widely used techniques in time series analysis, and often apply to other applications. These operations are dependent on having an ordering, particularly time ordering for temporal data. Three common types of variations for sliding window operations are:
- slide: sliding window with overlapping observations.
- tile: tiling window without overlapping observations.
- stretch: fixing an initial window and expanding to include more observations.
Figure 3.4 shows animations of rolling windows for sliding, tiling and stretching on annual tuberculosis cases for Australia. A block of consecutive elements with a window size of 5 is initialized in each case, and the windows roll sequentially to the end of series, with average counts being computed within each window.
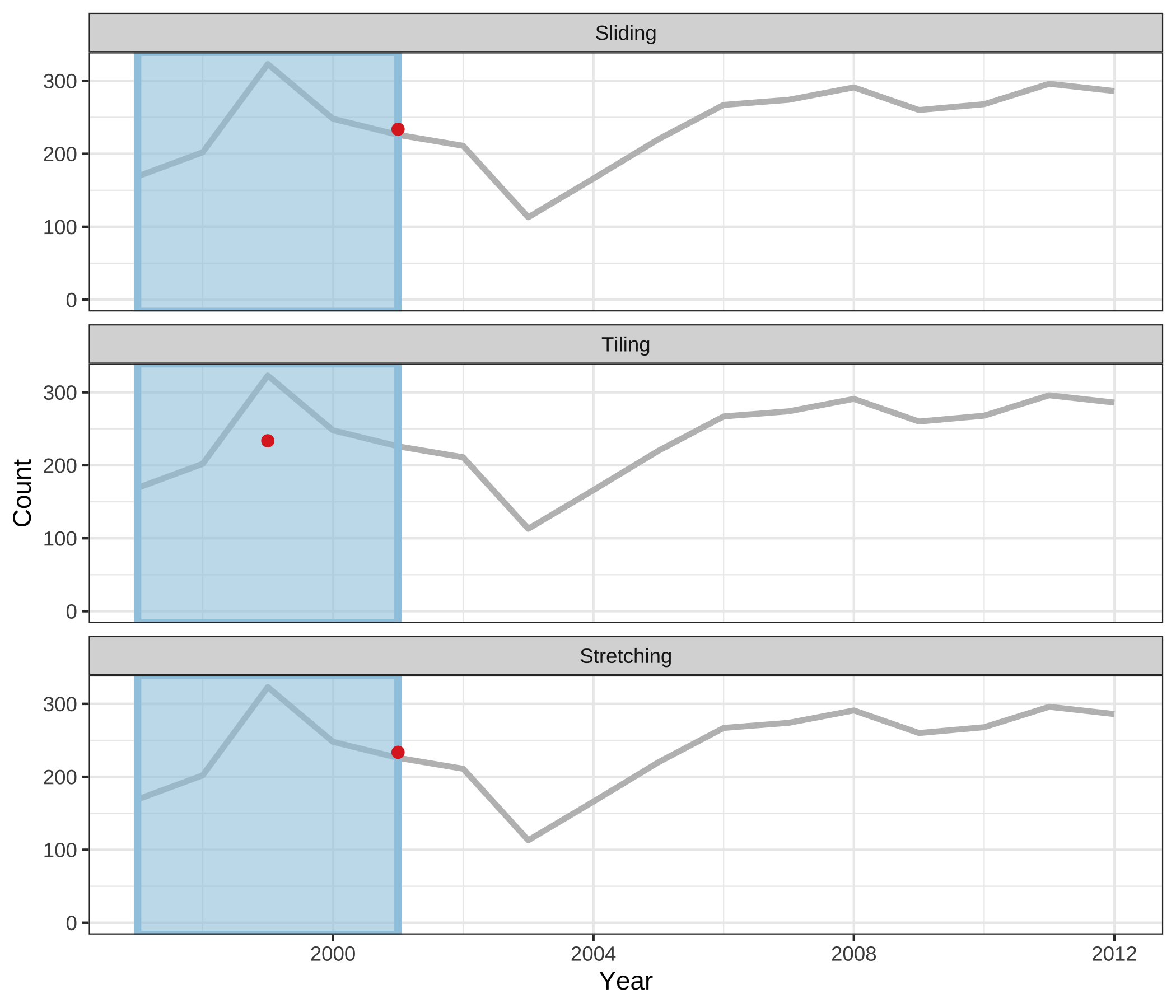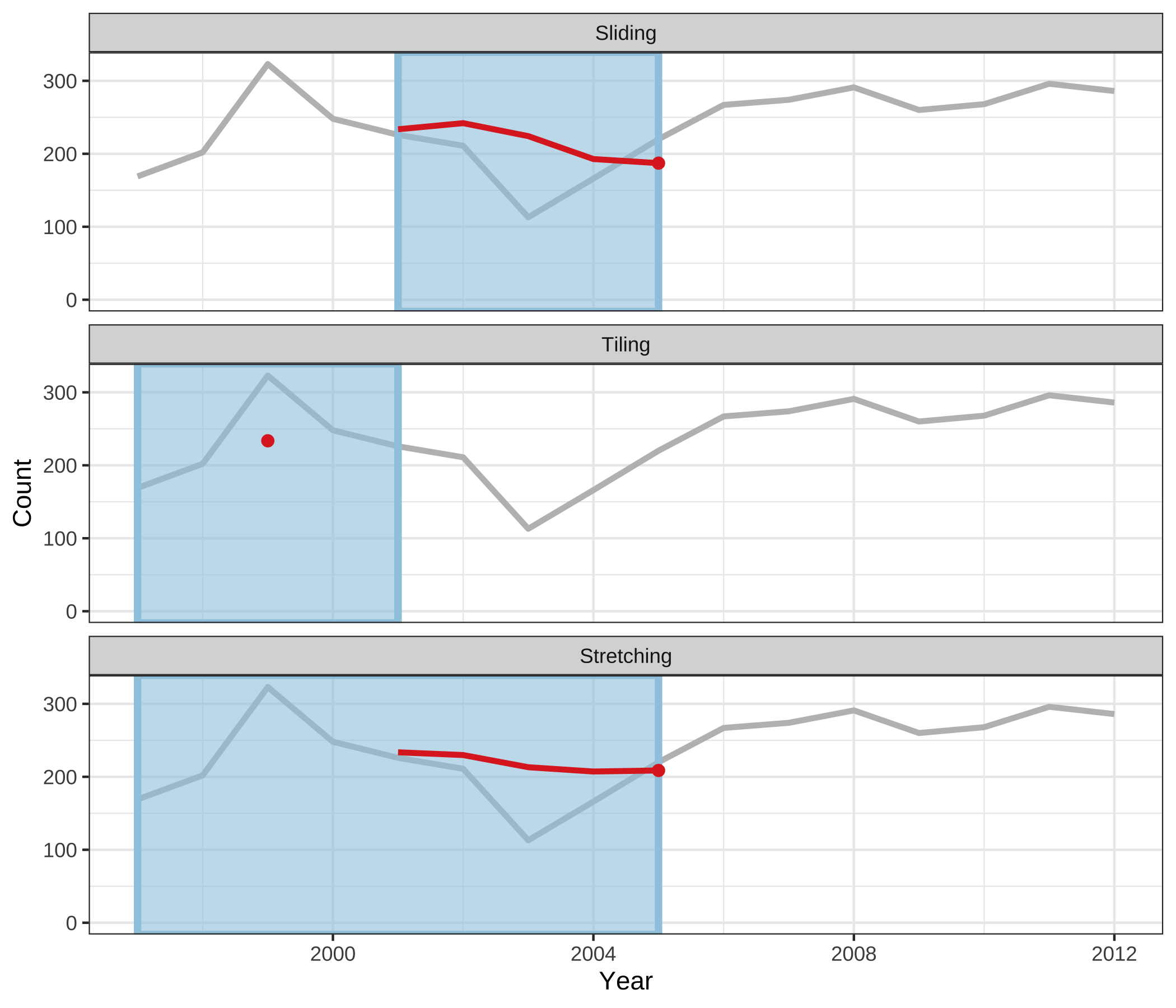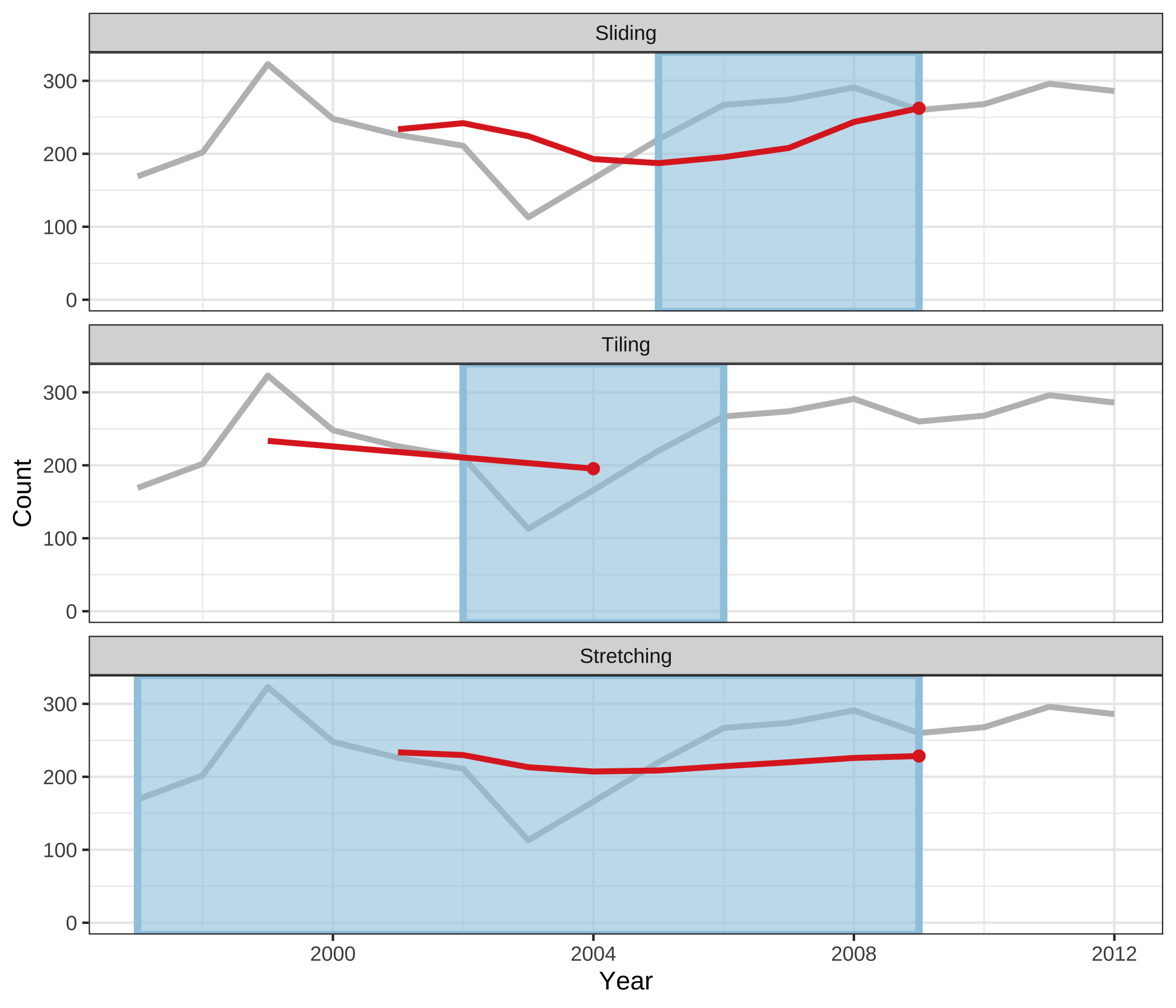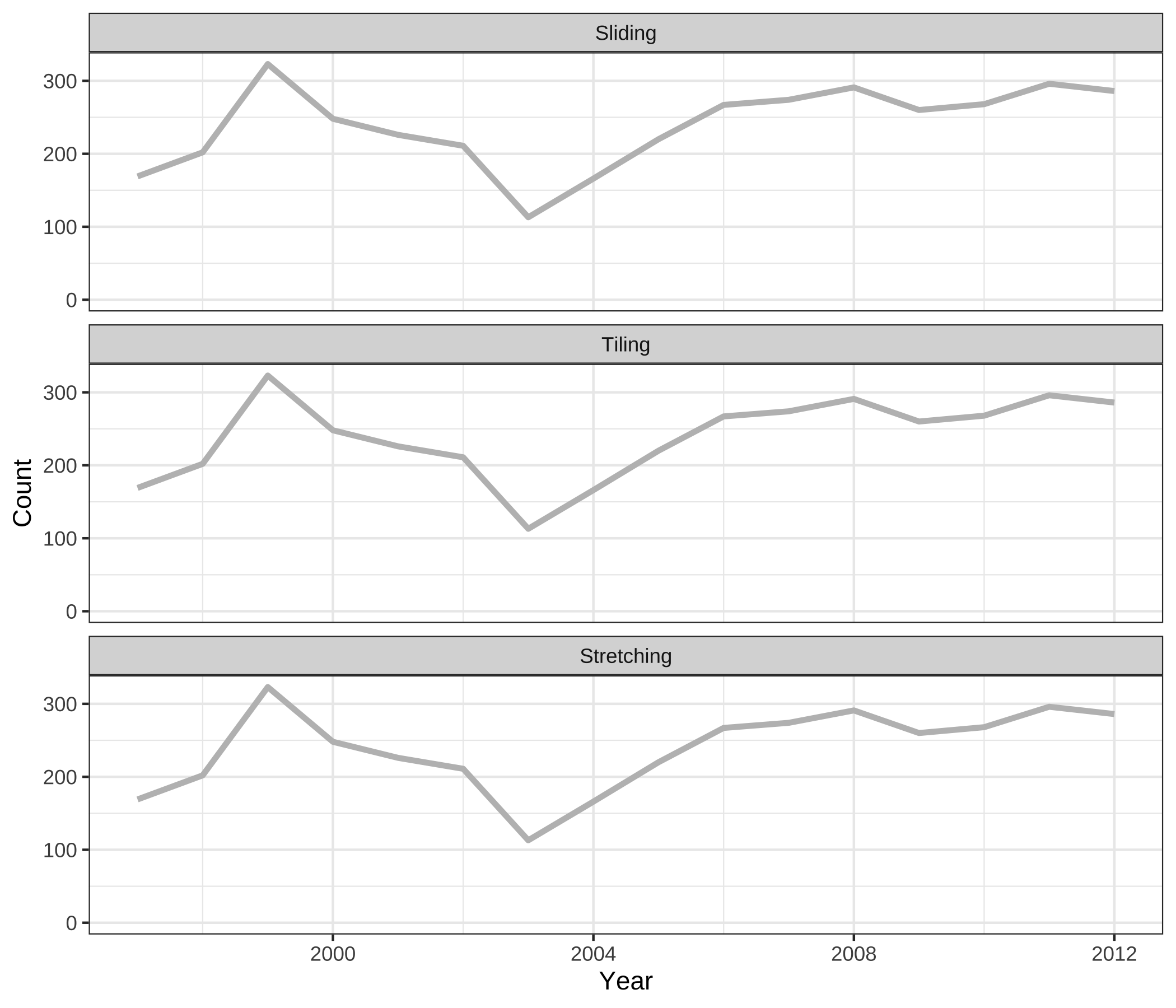
Figure 3.4: An illustration of a window of size 5 to compute rolling averages over annual tuberculosis cases in Australia using sliding, tiling and stretching. The animations are available with the supplementary materials online, and can also be viewed directly at https://github.com/earowang/paper-tsibble/blob/master/img/animate-1.gif.
{kind=link}
Rolling windows adapt to functional programming, for which the purrr package (Henry and Wickham 2019a) sets a good example. These functions accept and return arbitrary inputs and outputs, with arbitrary methods. For example, moving averages anticipate numerics and produce averaged numerics via mean(). However, rolling window regression feeds a data frame into a linear regression method like lm(), and generates a complex object that contains coefficients, fitted values, etc.
Rolling windows not only iterate but roll over a sequence of elements of a fixed window. A complete and consistent set of tools is available for facilitating window-related operations, a family of slide(), tile(), stretch(), and their variants. slide() expects one input, slide2() two inputs, and pslide() multiple inputs. For type stability, the functions always return lists. Other variants including *_lgl(), *_int(), *_dbl(), *_chr() return vectors of the corresponding types, as well as *_dfr() and *_dfc() for row-binding and column-binding data frames respectively. Their multiprocessing equivalents prefixed by future_*() enable rolling in parallel, via future (Bengtsson 2019) and furrr (Vaughan and Dancho 2018a).
3.5.3 Modularity
Modular programming is adopted in the design of the tsibble package. Modularity benefits users by providing small focused and cleaner chunks, and provides developers with simpler maintenance.
All user-facing functions can be roughly organized into three major chunks according to their functionality: vector functions (1d), table verbs (2d), and window family. Each chunk is an independent module, but works interdependently. Vector functions in the package mostly operate on time. The atomic functions (such as yearmonth() and yearquarter()) can be embedded in the index_by() verb to collapse a tsibble to a less granular interval. Since they are not tied to a tsibble, they can be used in a broader range of data applications not constrained to tsibble. On the other hand, the table verbs can incorporate many other vector functions from a third party, like the lubridate package (Grolemund and Wickham 2011).
3.5.4 Extensibility
As a fundamental infrastructure, extensibility is a design decision that was employed from the start of tsibble’s development. Contrary to the “data first” principle for end users, extensibility is developer focused and would be mostly used in dependent packages; it heavily relies on S3 classes and methods in R (Wickham 2018). The package can be extended in two major ways: custom indexes and new tsibble classes.
Time representation could be arbitrary, for example R’s native POSIXct and Date for versatile date-times, nano time for nanosecond resolution in nanotime (Eddelbuettel and Silvestri 2018), and numerics in simulation. Ordered factors can also be a source of time, such as month names, January to December, and weekdays, Monday to Sunday. The tsibble package supports an extensive range of index types from numerics to nano time, but there might be custom indexes used for some occasions, for example school semesters. These academic terms vary from one institution to another, with the academic year defined differently from a calendar year. A new index would be immediately recognized upon defining index_valid(), as long as it can be ordered from past to future. The interval regarding semesters is further outlined through interval_pull(). As a result, all tsibble methods such as has_gaps() and fill_gaps() will have instant support for data that contains this new index.
The class of tsibble is an underpinning for temporal data, and sub-classing a tsibble will be a demand. A low-level constructor new_tsibble() provides a vehicle to easily create a new subclass. This new object itself is a tsibble. It perhaps needs more metadata than those of a tsibble, that gives rise to a new data extension, for example prediction distributions to a forecasting tsibble.
3.5.5 Tidy evaluation
The tsibble packages leverages the tidyverse grammars and pipelines through tidy evaluation (Henry and Wickham 2019c) via the rlang package (Henry and Wickham 2019b). In particular, the table verbs extensively use tidy evaluation to evaluate computation in the context of tsibble data and spotlight the “tidy” interface that is compatible with the tidyverse. This not only saves a few keystrokes without explicitly repeating references to the data source, but the resulting code is typically cleaner and more expressive, when doing interactive data analysis.